
A ci/cd security product launch sounds like a security team problem until launch week starts. Then the founder is asking why the release is blocked, support is asking whether the hotfix is safe, and engineering is trying to remember which token has production deploy rights.
Teams think the problem is adding more security checks before launch. The real problem is knowing which parts of the shipping workflow can safely move fast, which parts need hard gates, and who owns the decision when something fails.
That changes the conversation. CI/CD security is not a definition exercise. It is a launch architecture problem: code becomes build, build becomes artifact, artifact becomes deployment, deployment becomes customer impact. If that chain is vague, your launch risk is vague.
The practical question is not whether you have a pipeline. It is whether your pipeline can survive the pressure of launch day without leaking secrets, shipping tampered artifacts, bypassing review, or making rollback harder than the original deploy.
Table of contents
- Why CI/CD security is a product launch problem
- Map the launch path before hardening CI/CD
- Threat model the pipeline like a launch surface
- Build gates that do not kill shipping speed
- Secrets, signing, and provenance for launch readiness
- Release controls for product launch day
- Observability and response when the pipeline misbehaves
- Common CI/CD security product launch failure modes
- A two-sprint implementation workflow
- Where sh1pt.com fits into a secure product launch
Why CI/CD security is a product launch problem
The pipeline is part of the product
For a startup, the product is not only the code users see. It is also the system that turns an idea into a working release. Your CI/CD pipeline is part of that system. It decides which code is allowed to build, which artifact is allowed to deploy, which environment is allowed to change, and which person or service can approve that change.
When the launch window is tight, this matters more than usual. A weak pipeline can ship the wrong commit. A loose token can give a compromised dependency access to production. A missing approval boundary can turn a harmless internal change into a public incident.
The mistake teams make is treating CI/CD security as a cleanup task after launch. In reality, launch is when the workflow is most stressed. More commits land. More people touch the release. More urgent fixes happen. More exceptions get requested.
Practical rule: If a control cannot survive launch pressure, it is not a launch control. It is documentation.
Launch pressure exposes hidden trust assumptions
Most teams have trust assumptions they have never written down. Maybe everyone with repository admin can change deployment workflows. Maybe the same cloud credential is used in staging and production. Maybe a self-hosted runner has access to internal networks and accepts jobs from pull requests.
None of this feels urgent while the team is small and moving quietly. Then launch turns a private workflow into a business-critical path. A customer-facing bug needs a hotfix. A contractor opens a pull request. A package update breaks the build. Someone disables a check to get the release out.
What breaks in practice is not always the scanner or the tool. It is the absence of a clear trust model.
Security gates should protect momentum
Security that only says no will be routed around by a team trying to launch. Security that gives clear routes will usually be followed.
A useful way to think about it is traffic control. Some checks are stop signs. Some are yield signs. Some are advisory signs. If every finding blocks the merge, developers stop trusting the system. If nothing blocks the merge, customers inherit the risk.
A CI/CD security product launch plan should define which issues block, which issues create tickets, which issues require human approval, and which issues are accepted for the launch window with an owner and expiration date.
Map the launch path before hardening CI/CD
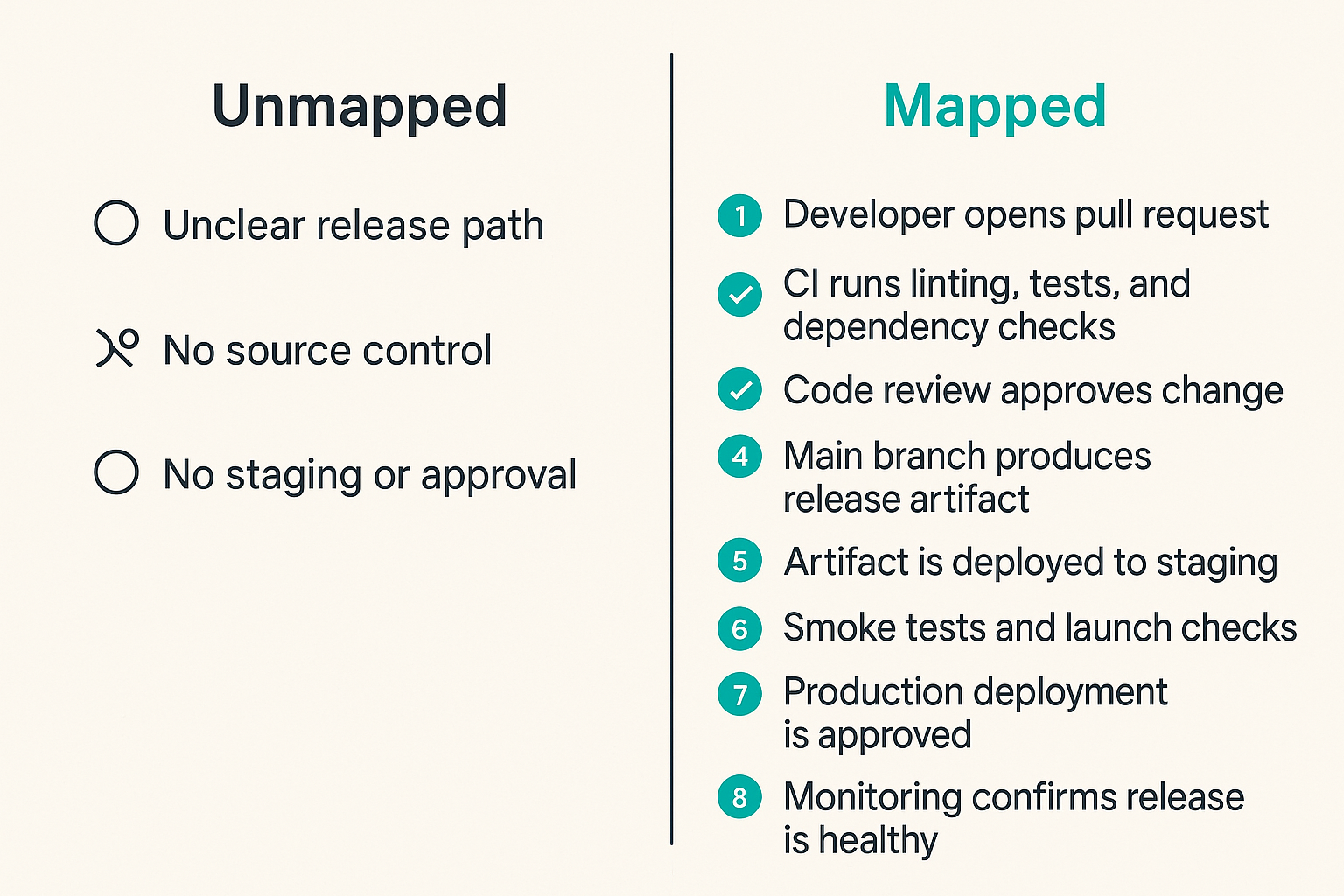
Start with the path to production
Before adding tools, draw the path to production. Not the ideal version. The actual version.
A simple launch path often looks like this:
- Developer opens pull request.
- CI runs linting, tests, dependency checks, and build.
- Code review approves the change.
- Main branch produces a release artifact.
- Artifact is deployed to staging.
- Smoke tests and launch checks run.
- Production deployment is approved.
- Monitoring confirms the release is healthy.
Once the path is visible, the weak spots are easier to see. Who can edit the workflow file? Who can approve production? Can the artifact change between staging and production? Are secrets available during pull request builds? Can a failed scan be skipped without leaving evidence?
The team at vu1nz.com has seen the same pattern across CI/CD and software supply chain work: the highest-risk issues often live in the gaps between tools, not inside a single scanner output.
Separate build trust from deploy trust
Build trust and deploy trust are different. A workflow that can compile code should not automatically have the power to change production. A test job should not need production secrets. A pull request from an untrusted branch should not run on a privileged runner.
This separation is especially important for indie hackers and small teams because convenience tends to collapse boundaries. One all-powerful token feels efficient until it becomes the single credential every job, script, and integration depends on.
A better model is narrow permission by stage:
| Stage | Needs access to | Should not access |
|---|---|---|
| Pull request checks | source code, test fixtures | production secrets, deploy keys |
| Build on main | package registry, artifact store | production admin credentials |
| Staging deploy | staging credentials | production data, production deploy keys |
| Production deploy | approved artifact, production deploy role | source control admin, unrelated cloud roles |
This table is not about bureaucracy. It is about blast radius. If a test job is compromised, it should not become a production incident.
Define what must never be manual
Manual steps are not automatically bad. Manual approval for production can be useful. Manual copying of artifacts is usually not. Manual secret injection during launch week is worse.
Decide which steps must be automated because humans are likely to make mistakes under pressure:
- Version tagging.
- Artifact promotion.
- Deployment logs.
- Rollback commands.
- Secret retrieval.
- Release note generation.
- Environment selection.
Practical rule: Automate anything where the wrong copy-paste command could ship the wrong build, expose a secret, or make rollback ambiguous.
Threat model the pipeline like a launch surface
Source control risks
Source control is the front door of the launch system. If an attacker or careless user can change workflow definitions, branch protections, dependency files, or deployment scripts, the rest of the pipeline inherits that risk.
For launch readiness, review these controls:
- Branch protection on release branches.
- Required reviews for workflow changes.
- CODEOWNERS or equivalent ownership on deployment files.
- Restricted force pushes and tag deletion.
- Clear rules for who can create release tags.
- Audit logs enabled for repository settings.
The practical question is simple: can someone change how production deploys without the right people noticing before the deploy happens?
Runner and build environment risks
CI runners are often treated as disposable compute. That is partly true, but only if they are actually isolated, short-lived, and scoped correctly.
Self-hosted runners deserve extra care. They can be useful for speed, private network access, mobile builds, or specialized dependencies. They can also become a bridge between untrusted code and internal systems.
Common runner mistakes include:
- Running pull request jobs from forks on privileged self-hosted runners.
- Reusing workspaces without cleaning them.
- Allowing build scripts to access broad environment variables.
- Installing long-lived cloud credentials on the runner host.
- Giving runners access to internal networks they do not need.
For launch, the safest default is ephemeral runners for sensitive jobs and strict separation between untrusted PR checks and privileged deploy workflows.
Dependency and artifact risks
Modern product launches rely on package managers, build plugins, containers, base images, and third-party actions. That is normal. It also means your launch artifact contains decisions made outside your team.
You do not need to freeze all dependencies forever. You do need a policy for what changes during launch.
A sane approach:
- Lock dependency versions for release candidates.
- Pin CI actions and build plugins to specific versions or commits where possible.
- Generate a software bill of materials if your ecosystem supports it.
- Store immutable build artifacts.
- Promote the same artifact from staging to production instead of rebuilding.
The key is repeatability. If production is built differently from staging, staging did not test the thing you shipped.
Build gates that do not kill shipping speed
Use fast checks early and expensive checks late
Not every security check belongs in every stage. Fast checks should run where developers get immediate feedback. Slower checks should run where they inform release decisions without blocking every small edit.
A practical split looks like this:
| Check type | Best stage | Launch behavior |
|---|---|---|
| Secret scanning | pull request and pre-merge | block confirmed secrets |
| Static analysis | pull request | block high-confidence critical issues |
| Dependency scan | pull request and release candidate | block exploitable critical issues |
| Container scan | build artifact | block critical runtime exposure |
| IaC scan | infrastructure PR | require review for risky changes |
| Dynamic smoke tests | staging | block production promotion |
The mistake teams make is turning every tool to maximum strictness during the week before launch. That produces noise when the team has the least time to triage it.
Treat severity as a routing rule
Severity should route work. It should not replace judgment.
For example, a critical vulnerability in a package that is not reachable in your deployed service is different from a critical vulnerability in your public request path. A medium issue involving a leaked staging credential may deserve more urgency than a theoretical high issue in dev-only tooling.
Define routing rules before launch:
- Block: confirmed secret exposure, production credential misuse, unsigned artifact, critical reachable vulnerability, failed smoke test.
- Require approval: new privileged workflow, infrastructure permission expansion, dependency major upgrade, bypass request.
- Create ticket: low-confidence static finding, non-reachable dependency issue, hardening improvement.
- Accept temporarily: documented issue with owner, customer impact assessment, and expiration date.
Practical rule: A launch gate should explain the next action. If it only says failed, it creates delay instead of control.
Keep bypasses visible and reviewable
Bypasses are part of real shipping. The goal is not to pretend they never happen. The goal is to make them deliberate.
A good bypass has:
- A named owner.
- A reason tied to the launch or incident.
- A specific control being bypassed.
- A time limit.
- A ticket or record to revisit it.
- Approval from someone who owns the risk.
A bad bypass is a disabled workflow, a commented-out check, or a one-off deploy command copied from chat.
If the team is small, this can be lightweight. A pull request comment and a tagged issue may be enough. What matters is that the bypass is visible to future you.
Secrets, signing, and provenance for launch readiness
Short-lived credentials beat shared tokens
Secrets management is where many launches quietly accumulate risk. The product needs payment keys, database credentials, API tokens, deployment roles, analytics credentials, and support tooling access. CI/CD needs some of those, but usually far fewer than teams think.
Prefer short-lived credentials issued to the workflow at runtime. Use identity federation where your CI provider exchanges a trusted workflow identity for a scoped cloud role. Avoid storing long-lived production secrets as repository variables unless there is no practical alternative.
If you must store secrets in the CI system, apply basic discipline:
- Scope secrets to environments.
- Restrict who can read or modify them.
- Avoid exposing secrets to pull request jobs from forks.
- Rotate launch-critical secrets after a suspected leak.
- Do not print secrets in build logs, even masked ones.
The point is not to make secrets perfect. The point is to ensure one compromised job cannot become an all-access pass.
Signed artifacts make rollback safer
Signing sounds like enterprise overhead until you need to know which artifact is safe to deploy during a stressful rollback.
A signed artifact gives you a stronger answer to three questions:
- Was this artifact produced by the expected workflow?
- Has it changed since it was built?
- Is this the same artifact that passed staging checks?
For a launch, signing is less about compliance and more about confidence. If production starts failing, the team should not debate whether the rollback build came from someone’s laptop, an old CI run, or a rebuilt dependency tree.
A minimal pattern:
release:
build: create immutable artifact
sign: attach signature and digest
store: push to artifact registry
promote: deploy by digest only
Provenance answers the launch-week audit question
Provenance is the story of how an artifact came to exist. Who triggered the build? From which commit? With which workflow? On which runner? With which dependencies? Where was it stored? Who approved deployment?
You may not need a formal attestation framework on day one. But you do need enough traceability to answer what shipped.
During launch, that answer affects support, security, debugging, and customer communication. If a customer reports a bug, you need to map it to a version. If a credential leaks, you need to know which jobs had access. If a dependency is compromised, you need to know which releases included it.
Release controls for product launch day
Feature flags are not a substitute for deployment control
Feature flags are useful. They let teams separate deployment from exposure. They are especially helpful for staged rollouts, beta users, pricing tests, and emergency kill switches.
But flags do not replace secure deployment controls. A bad deployment can still break migrations, background jobs, permissions, infrastructure, or shared libraries. A compromised pipeline can still push malicious code behind a disabled flag.
Use feature flags as a release management tool, not as an excuse to weaken the path to production.
Use environments as policy boundaries
Environments should mean more than different variable names. They should carry different rules.
For example:
- Preview environments can be created automatically but cannot access production data.
- Staging can deploy from main but uses staging credentials.
- Production requires an approved release artifact and explicit approval.
- Emergency production deploys require a separate break-glass path with logging.
This helps product teams move fast without pretending every environment has the same risk.
Rollback needs the same security model as deploy
Rollback is often treated as a panic button. That is dangerous. If rollback can deploy arbitrary old artifacts without verification, it can become a bypass around your normal release controls.
A good rollback process deploys a known signed artifact, records who triggered it, runs post-deploy checks, and keeps the incident timeline clear.
The practical question is not can we roll back. It is can we roll back safely at 2 a.m. without inventing a new process.
Observability and response when the pipeline misbehaves
Log decisions, not just job output
CI logs are full of output and often light on decisions. For launch readiness, you want to know why a deployment was allowed, blocked, bypassed, or rolled back.
Capture events such as:
- Workflow file changed.
- Branch protection changed.
- Secret updated.
- Production deployment approved.
- Security gate failed.
- Security gate bypassed.
- Artifact promoted.
- Rollback triggered.
These events are useful during incidents and post-launch reviews. They also discourage quiet shortcuts.
Alert on unsafe workflow changes
The CI/CD system is code, and changes to it should be monitored like changes to application code. In some cases, they deserve more attention.
Alert or require review when someone changes:
- Deployment workflows.
- Permission scopes.
- Runner labels.
- Secret names or environment mappings.
- Release branch rules.
- Artifact registry settings.
This is where small teams often get real leverage. You may not have a large security function, but you can still make dangerous changes visible.
Practice incident paths before launch
A launch rehearsal should include security-flavored failure modes, not just happy-path deploys.
Try these drills:
- A dependency scan blocks the release candidate.
- A production deploy fails halfway through.
- A secret appears in a build log.
- A workflow file changes unexpectedly.
- A rollback is needed after a migration.
The point is not theater. The point is reducing decision time when the team is tired and customers are watching.
Common CI/CD security product launch failure modes
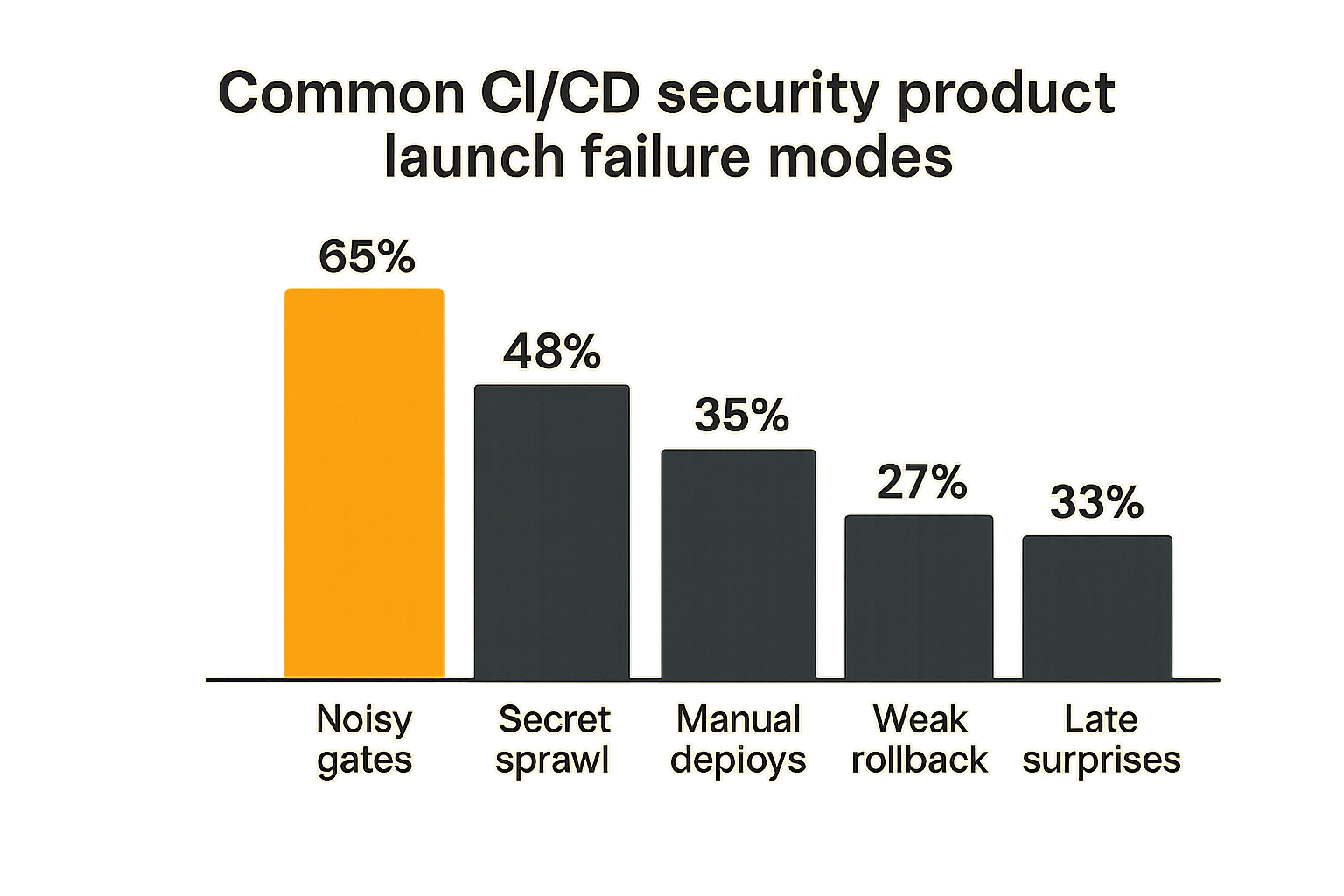
What fails when security is bolted on
Bolted-on security usually fails in predictable ways.
First, it creates noisy gates. Developers see a wall of findings with no routing, no ownership, and no explanation of launch impact. They learn to ignore the output or pressure someone to disable it.
Second, it creates invisible exceptions. A check is skipped. A workflow is edited. A token is broadened. Nobody documents it because the team is trying to ship.
Third, it creates late surprises. The first time a release candidate sees the full security pipeline is two days before launch, and now the team has to choose between delay and unknown risk.
That is not a tooling failure. It is a workflow design failure.
What works in small teams
Small teams do not need enterprise process. They need clear defaults.
What works:
- One protected release path.
- Few production deployers.
- Environment-scoped secrets.
- Required review for workflow changes.
- Fast checks on pull requests.
- Artifact promotion instead of rebuilds.
- Simple bypass records.
- Practiced rollback.
The founder-friendly version is this: fewer paths, fewer secrets, fewer mysteries.
What to avoid during the final week
The final week before launch is a bad time to introduce complicated controls nobody has used. It is also a bad time to leave obvious holes open because everyone is busy.
Avoid:
- Replacing your whole CI provider.
- Turning on every scanner in blocking mode.
- Moving production credentials into new places without testing.
- Changing runner architecture unless required.
- Allowing undocumented manual deploys.
- Shipping from local machines.
If a control is new, rehearse it. If a shortcut is needed, document it. If a risk is accepted, put a name and date on it.
A two-sprint implementation workflow
Sprint one: inventory and guardrails
For most product teams, the right move is not a six-month security program. It is two focused sprints before launch.
Sprint one is about visibility and basic guardrails.
- Map the release path from pull request to production.
- List every credential used by CI/CD.
- Identify who can edit deployment workflows.
- Separate untrusted PR jobs from privileged jobs.
- Turn on branch protection for release branches.
- Require review for workflow and infrastructure changes.
- Pin critical build actions, images, and dependencies.
- Store release artifacts immutably.
This sprint should produce a simple diagram, a credential inventory, and a short list of policy decisions. If it produces only a spreadsheet nobody uses, it failed.
Sprint two: enforcement and rehearsal
Sprint two turns decisions into launch behavior.
- Add fast security checks to pull requests.
- Add release candidate checks before production promotion.
- Define blocking, approval, ticket, and accepted-risk categories.
- Implement environment-scoped secrets.
- Require approval for production deploys.
- Deploy by artifact digest or immutable version.
- Test rollback from a signed or verified artifact.
- Run a launch rehearsal with one failed gate and one rollback.
The output should be a pipeline that the team has already used under controlled stress. Not a perfect pipeline. A known pipeline.
The launch readiness checklist
Use this checklist before you call the release ready:
- Can we identify the exact commit and artifact shipping to production?
- Can pull request jobs access production secrets? If yes, why?
- Can one person change deployment logic without review?
- Are production credentials scoped and short-lived where possible?
- Are release artifacts immutable?
- Do security gates have clear routing rules?
- Is every bypass visible and time-bound?
- Can we roll back without rebuilding?
- Do we alert on workflow, secret, and branch rule changes?
- Has the team practiced a failed deploy and rollback?
Practical rule: Launch readiness is not the absence of findings. It is the presence of known decisions, known owners, and known recovery paths.
Where sh1pt.com fits into a secure product launch
Shipping strategy includes pipeline strategy
A product launch plan that ignores CI/CD is incomplete. The launch calendar, beta plan, feature freeze, release notes, support coverage, monitoring, and rollback plan all depend on the same pipeline reality.
For builders, this is the useful framing: CI/CD security product launch planning is not about slowing down. It is about making the shipping system predictable enough that you can move faster without gambling on hidden assumptions.
When teams plan launches on sh1pt.com, the security piece should sit beside the product and growth work. What are we shipping? Who approves it? How do we know it is the right build? What happens if it fails? Who can change the release path? Those are launch questions, not just security questions.
Use launch planning to reduce security theater
Security theater shows up when teams add visible controls that do not change outcomes. A scanner nobody reads. A manual approval everyone rubber-stamps. A policy document that does not match the pipeline. A launch checklist that says security reviewed without saying what was reviewed.
What works is smaller and more concrete:
- Protect the release path.
- Limit production credentials.
- Verify artifacts.
- Route findings by action.
- Record exceptions.
- Practice rollback.
That is enough to materially reduce launch risk for many small teams. It also creates a foundation you can mature later as the product, team, and customer expectations grow.
The closing point is simple: a ci/cd security product launch is not a ceremony. It is the operating system for shipping software when the stakes are higher than usual.
Try sh1pt.com
sh1pt.com helps founders, indie hackers, and product teams turn shipping into a repeatable launch workflow. Try sh1pt.com