
Most indie teams ship their first version and immediately face the same crisis: the feedback loop breaks. Users trickle in, a few report bugs, some request features, and the founder — who just spent three months building — has no system for deciding what to do next. The product stagnates not because the team is lazy but because the architecture of how they ship was never designed for continuity.
The pattern that emerges is familiar. Big bang releases followed by silence. A sprint to fix critical bugs. Another big push. More silence. The team oscillates between two modes — heads-down building and reactive firefighting — and never develops the kind of steady shipping cadence that compounds over time.
Teams think the problem is prioritization. The real problem is granularity. They're shipping in chunks too large to learn from and too infrequent to maintain momentum. Peptide software development is the architectural answer to that problem. It's not a methodology with a certification program. It's a way of structuring how you decompose, ship, and validate work so that every release is small enough to be reversible and coherent enough to be meaningful.
This post breaks down how that model works in practice — the workflows, the failure modes, and the concrete decisions that separate teams that use it well from teams that just fragment their roadmap without intent.
Table of contents
- What peptide software development actually means
- The core shipping model
- How peptide cadence changes your feedback loop
- Decomposition patterns that work
- Sequencing: the order of units matters more than the units themselves
- Common failure modes
- What breaks in practice
- Comparison: monolithic vs. peptide shipping
- Implementation sequence for solo founders and small teams
- Connecting peptide development to payment and infrastructure layers
- Product fit: using sh1pt.com to maintain peptide cadence
What peptide software development actually means
The term borrows deliberately from biochemistry. A peptide is a short chain of amino acids — not a full protein, not a single molecule, but a functional unit that combines with others to produce complex biological effects. The analogy is apt because it captures something that most shipping frameworks miss: the unit of work is neither atomic nor monolithic. It has internal structure, it has interfaces to adjacent units, and its value is partially dependent on sequence.
The amino acid analogy without the hype
Don't overthink the metaphor. The useful part is this: amino acids in isolation don't do much. Proteins in isolation are hard to modify. Peptides are the productive middle — small enough to synthesize quickly, structured enough to have predictable behavior, and composable enough to combine into something larger.
In software terms, a peptide unit is a shippable increment that delivers one clear capability, can be validated independently, and connects to adjacent increments through defined interfaces. It's bigger than a commit. It's smaller than a feature milestone. It's the granularity at which learning happens.
Why granularity is an architectural decision
Most teams treat granularity as a planning preference — some people like big stories, some like small tasks. Peptide software development treats granularity as an architectural constraint. The size of your shipping unit determines the resolution of your feedback, the cost of reversal, and the cognitive load of your releases.
Practical rule: If a release takes more than one paragraph to explain in your changelog, it's probably too large to learn from cleanly.
The mistake teams make is conflating granularity with scope reduction. Shipping smaller doesn't mean shipping less value. It means structuring value delivery so that each unit can be evaluated on its own terms before it's compounded with the next.
The core shipping model
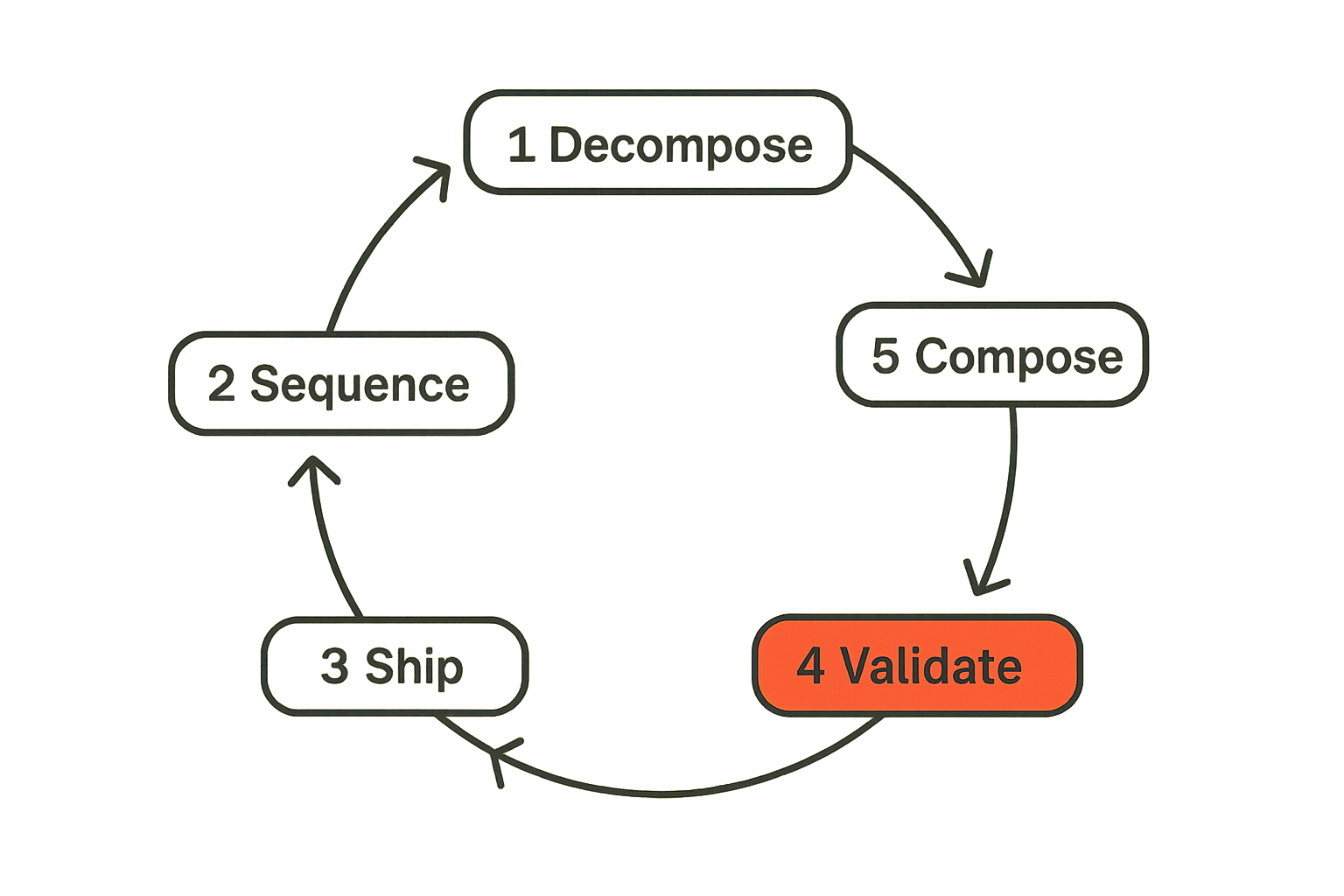
Peptide software development operates on a simple model: decompose, sequence, ship, validate, compose. Each of those verbs is load-bearing. Skip validation and you're just doing small waterfall. Skip composition and you're shipping features that never cohere into a product.
Decomposing work into peptide units
Decomposition is where most teams go wrong. They take a roadmap item — say, "user onboarding" — and either ship it all at once or break it into tasks that aren't independently shippable. Neither produces useful signal.
A peptide decomposition of user onboarding might look like this:
- Signup form with email verification (no onboarding flow yet)
- First-login empty state with a single call to action
- Guided step one only, skippable
- Progress persistence across sessions
- Completion state and next-step prompt
Each unit ships and runs in production. Each generates data. Unit 3 tells you whether users engage with guidance at all before you've invested in units 4 and 5.
The release boundary problem
The hardest part of decomposition isn't identifying small units — it's deciding where one unit ends and the next begins. That boundary is not arbitrary. It should correspond to a question you want answered.
Practical rule: Each peptide unit should correspond to one falsifiable hypothesis about user behavior or system performance. If you can't name the hypothesis, the boundary is wrong.
Teams that skip this step end up with units that are small but directionless. You ship frequently but you don't know what you're learning. The cadence is there; the intelligence isn't.
How peptide cadence changes your feedback loop
The feedback loop is the real reason to care about peptide shipping. When you ship monthly, you get monthly signal. When you ship weekly, you get weekly signal. But it's not just frequency — it's signal quality.
Signal density vs. signal noise
Smaller releases produce cleaner signal because there are fewer variables. When a user churns the week after a 40-feature release, you don't know which of the 40 features caused the friction. When they churn the week after a single-unit release, the diagnostic space is small.
This is the practical reason peptide shipping compounds over time. Each release teaches you something you can actually act on. The team at coinpayportal.com applies this logic to payment infrastructure: shipping billing and checkout changes in small, validated increments rather than platform-wide overhauls, because the cost of a bad signal in payments is high and the surface area for failure is large.
What a healthy cadence looks like in production
In practice, healthy peptide cadence for a solo founder or two-person team looks like:
- One shippable unit per week, every week
- A changelog entry that names the hypothesis being tested
- A 48–72 hour observation window before the next unit ships
- A standing review (even if solo) of what the last unit taught you
That's not glamorous. It's not a launch event. But it compounds. Twelve weeks of that cadence produces twelve data points and a product that's been shaped by real usage, not by the roadmap you wrote before you had users.
Decomposition patterns that work
There are two decomposition patterns that consistently produce good peptide units. Most teams use neither by default.
Vertical slicing over horizontal layering
Horizontal decomposition means building a full layer before adding the next: complete the data model, then the API, then the UI. Vertical slicing means shipping a thin, end-to-end capability — even a crude one — that touches all layers at once.
Vertical slices produce shippable units. Horizontal layers produce internal milestones that users can't interact with. The practical test: can a user touch this in production? If no, it's a layer, not a unit.
Feature flags as peptide scaffolding
Feature flags are the infrastructure that makes peptide shipping safe at speed. They let you merge code without exposing it, roll out to a subset of users, and roll back without a deployment. They're not a luxury for large teams — they're the mechanism that makes small, frequent releases recoverable.
For solo founders, even a simple boolean in your config or a row in a database table is enough. The point is separating deployment from activation so that your release boundary is a decision, not a side effect of your deploy pipeline.
Practical rule: Treat every peptide unit as potentially reversible. If you can't roll it back without a full redeploy, you haven't finished the unit's infrastructure.
Sequencing: the order of units matters more than the units themselves
This is the part of peptide software development that most articles skip. You can have perfectly sized units and still build the wrong thing if you sequence them poorly. Sequence determines what you learn first, what you build on top of, and what you have to undo when a unit fails.
Load-bearing vs. exploratory units
Not all units are equal. Some are load-bearing — they define the structural constraints that subsequent units depend on. Others are exploratory — they test an assumption without committing to an architecture.
The mistake teams make is shipping exploratory units on top of load-bearing assumptions that haven't been validated yet. You build the detailed onboarding flow before you've confirmed users actually want guided setup. When the assumption fails, you've compounded the cost.
Sequence load-bearing validations first. Ship the structural commitments only after the exploratory units confirm the direction.
Building a dependency map before you ship
Before you start a peptide sprint, map the dependencies between your units. Which units assume user state from a previous unit? Which units write to a schema that other units read? Which units expose a public interface that you'll be reluctant to change?
A simple list is enough. You're looking for hidden coupling — units that look independent but share a data model or a UI contract. Those need to be sequenced carefully or decoupled before they ship.
Common failure modes
Peptide software development fails in consistent ways. Knowing the failure modes in advance is more useful than any framework diagram.
Fragment drift
Fragment drift is when your units stop connecting to each other. You ship a lot, but the product never coheres. Each unit was locally sensible but globally incoherent. Users experience the product as a collection of features, not a system.
This happens when teams optimize for cadence without maintaining a coherent product narrative. The fix is a standing review of how recent units compose into user journeys — not just whether each unit worked in isolation.
Coherence collapse
Coherence collapse is the extreme version of fragment drift. The product becomes internally inconsistent — different interaction patterns in different sections, conflicting data models, user flows that don't connect. This is recoverable but expensive. It usually requires a consolidation sprint that ships no new capability, which is demoralizing after weeks of forward momentum.
The prevention is ruthless narrative review. Before every unit ships, ask: does this fit the product as it exists today, or does it require the user to learn a new mental model?
The micro-release trap
Some teams take peptide thinking too far and ship units so small they're meaningless to users. A one-line copy change. A color adjustment. A tooltip. These aren't peptide units — they're maintenance commits. Shipping them as releases dilutes your changelog, trains users to ignore your updates, and produces no useful signal.
That changes the conversation about what "small" means. Small relative to a major feature release. Not small relative to user perception. A peptide unit should be noticeable to a user even if it's modest in scope.
What breaks in practice
When teams apply peptide logic to the wrong layer
Peptide thinking works at the product and feature layer. It doesn't work well at the infrastructure layer without modification. Infrastructure changes — database migrations, API version bumps, auth system replacements — have coupling properties that make them dangerous to ship in small increments without explicit migration strategies.
Many teams learn this the hard way when they try to migrate a schema incrementally and end up with three weeks of dual-write logic and a production environment that's in an undefined intermediate state. Peptide decomposition at the infrastructure layer requires expand-contract patterns, not just small PRs.
Tooling mismatches that kill the cadence
The second practical failure is tooling friction. If your deployment pipeline takes 40 minutes to run, weekly shipping is painful. If your feature flag system requires a backend engineer to flip, exploratory units become slow. If your changelog is a manual process, you'll skip it.
The tooling has to match the cadence. That means: fast CI/CD, lightweight feature flags, and a changelog process that takes less than five minutes. If any of those are missing, the cadence will degrade under pressure.
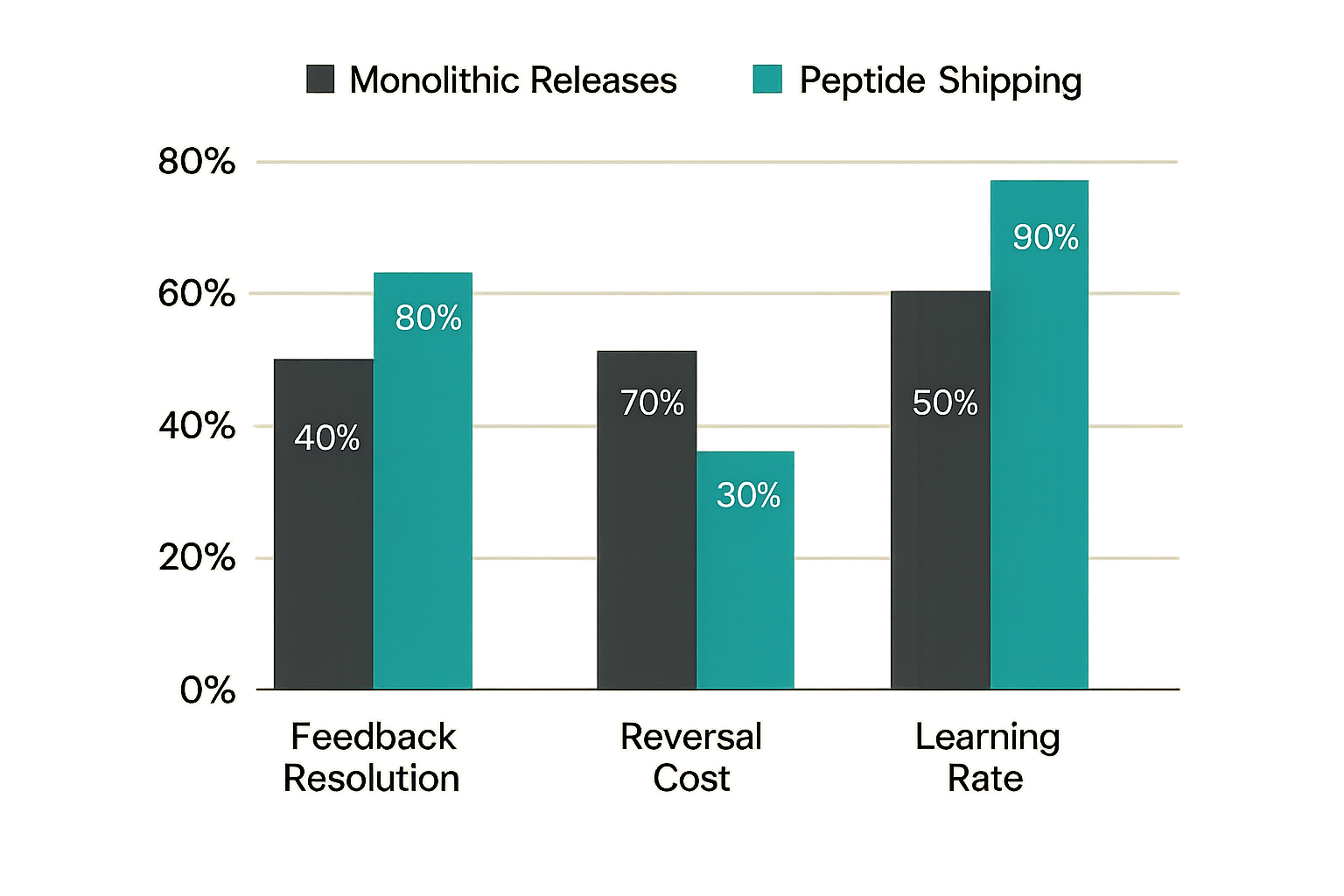
Comparison: monolithic vs. peptide shipping
| Dimension | Monolithic releases | Peptide shipping |
|---|---|---|
| Release frequency | Monthly or quarterly | Weekly or more often |
| Feedback resolution | Low (many variables) | High (few variables) |
| Reversal cost | High | Low to medium |
| User-visible momentum | Occasional bursts | Consistent progress |
| Cognitive load per release | High | Low |
| Coherence risk | Low per release | Requires active management |
| Learning rate | Slow | Fast, if validated correctly |
| Suitable team size | Any | Any, but especially small |
The table doesn't say peptide shipping is always better. Monolithic releases have advantages for products that need to ship a complete experience before any value is visible — hardware integrations, regulatory submissions, API versioning with external consumers. The practical question is: which model matches your feedback economics?
Implementation sequence for solo founders and small teams
Here's a concrete sequence for shifting to peptide shipping if you're currently operating in big-bang mode.
Week one: audit your current release shape
- List your last five releases and count the number of distinct user-visible changes in each.
- For each release, identify whether you could have shipped any single change independently and still had it be meaningful to a user.
- Map the questions you wanted each release to answer. Write them down honestly. If you can't name a question, mark that release as a learning gap.
- Identify the one thing in your current backlog that is both independently shippable and maps to a question you urgently need answered.
- Ship only that thing next week.
Weeks two through four: run a peptide sprint
- Take your next roadmap item and decompose it into vertical slices using the "can a user touch this?" test.
- Sequence the slices by dependency and validation priority — load-bearing validations first.
- Assign one slice per week.
- After each slice ships, write a one-paragraph observation: what happened, what it means for the next slice.
- At the end of week four, review the composition: do the three slices form a coherent capability, or do they feel like three separate features?
That four-week sequence will surface most of the friction in your current process — the deploy bottlenecks, the feature flag gaps, the changelog discipline failures. Fix those as they appear. Don't wait for a system overhaul.
Connecting peptide development to payment and infrastructure layers
Why checkout and billing infrastructure need peptide thinking too
For teams building products with paid tiers, checkout flows, or crypto payment rails, peptide thinking applies directly to the billing and payment layer — and the stakes are higher. A broken checkout is not just a failed experiment; it's lost revenue and support overhead.
The practical question is how you apply incremental shipping to a layer where partial states are dangerous. The answer is the same as infrastructure: expand-contract with explicit validation at each boundary. Ship the new payment method behind a flag, validate it with a cohort, confirm reconciliation is clean, then expand.
A useful way to think about it is: your checkout is a product, and it deserves the same peptide decomposition discipline as your onboarding or your dashboard. Shipping the payment flow as a single monolithic unit is exactly the pattern that produces mysterious drop-off you can't attribute.
Product fit: using sh1pt.com to maintain peptide cadence
The bottleneck for most indie teams running a peptide shipping model isn't motivation — it's infrastructure and accountability. The deploy is manual. The changelog is skipped. The observation window gets absorbed by support tickets. The cadence degrades without a system to hold it.
sh1pt.com is built for exactly this context: founders and small teams who want to ship consistently and publicly, with the kind of structured changelog and launch tooling that makes peptide cadence sustainable. The public shipping log creates accountability. The launch infrastructure reduces the friction between "unit is ready" and "unit is live."
If you're running peptide sprints in a spreadsheet and a Notion page, that works until it doesn't. A dedicated tool that's designed around frequent, incremental shipping removes the maintenance overhead from the system so the cadence can survive the weeks when everything else is on fire.
The fit isn't just workflow convenience. It's architectural: a tool designed for frequent shipping enforces the disciplines that peptide development requires — clear release notes, observable momentum, structured launch events — without requiring the team to invent that discipline from scratch.
Try sh1pt.com
sh1pt.com is the shipping platform for indie hackers, founders, and small product teams who want to build momentum through consistent, public progress. Stop shipping in bursts. Start compounding. Try sh1pt.com