
You built the product. It works. Early customers are using it. Then growth stalls — not because of bad marketing copy or the wrong pricing tier, but because the workflows you designed for five customers are quietly breaking under fifty.
This is the pattern almost every threat intelligence startup hits. The intelligence pipeline that felt elegant at small scale becomes a bottleneck. The alerting logic that worked for a homogeneous customer base produces noise the moment enterprise buyers show up with complex environments. The onboarding flow that worked when a founder handled every new account can't run without the founder anymore.
Teams think the problem is distribution. The real problem is that the product's operational model was never designed to grow. That's an architecture and workflow problem — and it shows up disguised as a sales problem, a support problem, or a retention problem.
This post is about recognizing that reframe early, and building the systems that let a threat intelligence product scale without falling apart.
Table of contents
- Why threat intelligence startup growth stalls differently
- The real architecture question: pipeline or platform?
- Reducing noise before it reaches customers
- Onboarding as a systems problem
- Data freshness and feed reliability
- Go-to-market architecture for security products
- Pricing as a workflow signal
- What breaks in production: common failure modes
- Building feedback loops into the product
- Scaling the team without scaling chaos
- Product-market fit for threat intelligence platforms
- Where sh1pt.com fits into the growth story
Why threat intelligence startup growth stalls differently
Most SaaS growth playbooks assume a relatively generic product-to-customer relationship: user signs up, user gets value, user tells friends. Threat intelligence products break this model almost immediately.
The value delivery is mediated. The customer doesn't experience your product directly — they experience the downstream effects of your intelligence inside their SIEM, their SOC workflow, or their endpoint tooling. If your data is good but the integration layer is rough, value is invisible. If your data is slightly off — a false positive rate that's 3% too high, a feed that lags by four hours — the analyst team turns your alerts off and never turns them back on.
The intelligence-to-signal conversion problem
Raw intelligence isn't value. Value is a correctly prioritized alert that an analyst can act on in three minutes. The conversion from raw threat data to actionable signal involves normalization, deduplication, scoring, contextual enrichment, and routing — and every one of those steps can silently fail.
The mistake teams make is treating their data pipeline as infrastructure and their product as the UI sitting on top of it. In practice, the pipeline is the product. Bugs in scoring logic aren't backend bugs — they're product defects that show up as analyst frustration and eventually as churn.
Practical rule: Instrument every enrichment step as if it's a customer-facing feature. If the scoring logic changes, treat it like a product release — version it, communicate it, and monitor it for regressions.
Context rot: when fresh data becomes stale noise
Threat intelligence has a half-life. An IP address flagged as malicious today may be running legitimate infrastructure in ninety days. A domain that was part of an active campaign last quarter may be parked or re-registered. If your product doesn't manage expiry and context decay, you're accumulating false positives that compound over time.
In production, teams often discover this problem when a customer escalates — not when the data goes stale. By that point, trust is already damaged. Designing TTL logic and context refresh cycles into the data model early is the unglamorous work that separates products that retain customers from products that don't.
The real architecture question: pipeline or platform?
Before you can grow, you need to know what you're actually building. Many threat intelligence startups muddle through the first twelve months without answering this question cleanly, and it costs them.
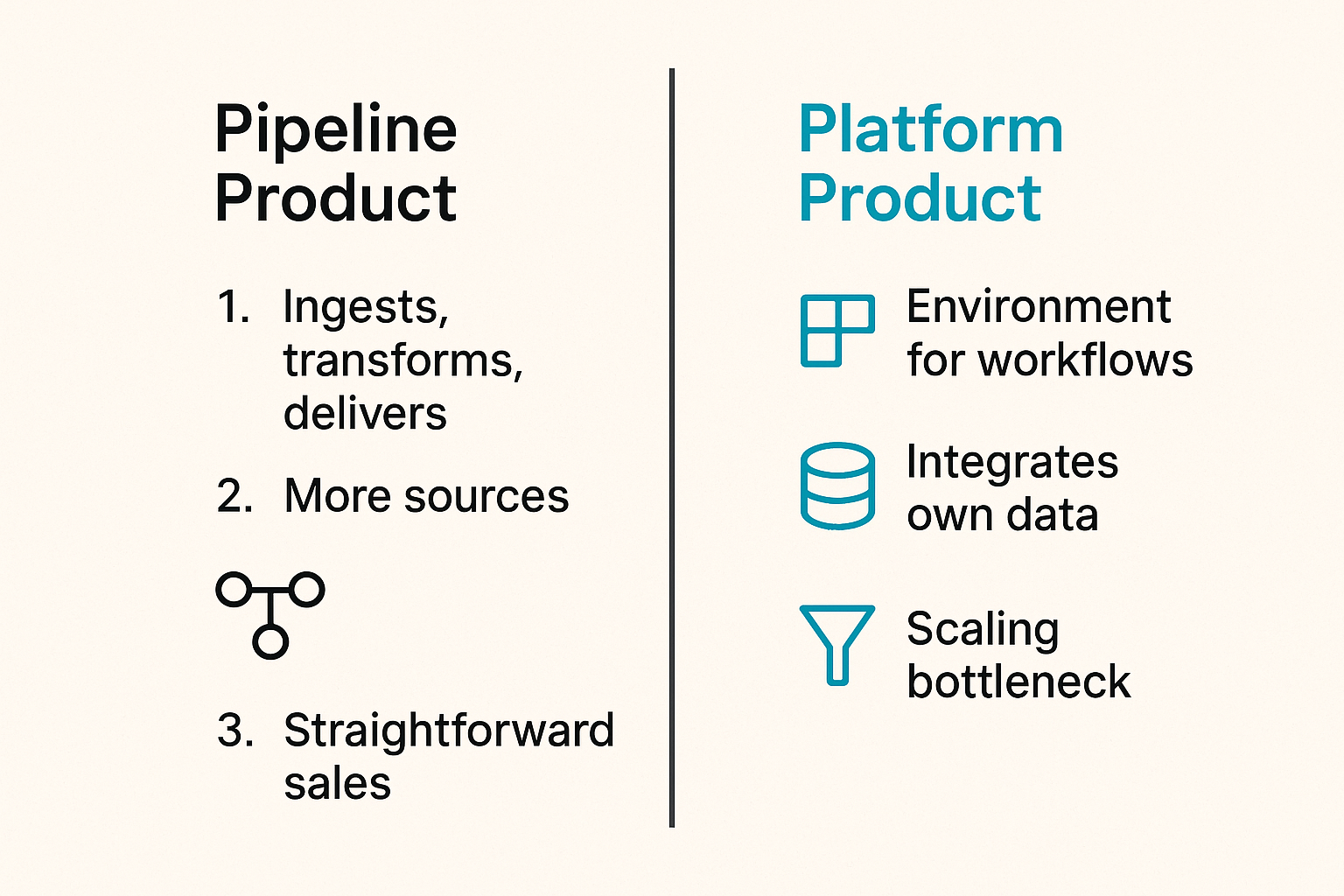
A pipeline product ingests data from sources, transforms it, and delivers it somewhere else. A platform product provides an environment where customers build workflows, integrate their own data, and customize output. These are fundamentally different investment bets — in engineering, in support, in sales motion, and in pricing.
When a pipeline is enough
If your customers want a specific, well-defined intelligence feed — say, high-confidence malicious IPs for firewall blocking, or daily threat actor TTPs for a security team briefing — a clean pipeline product is defensible. The moat is data quality, freshness, and reliability. You're competing on the signal, not on the workflow layer.
Growth here looks like: more sources, better deduplication, faster refresh rates, and integrations into the SIEM/SOAR destinations your customers already use. The sales motion is straightforward. The support burden is predictable. You can grow a meaningful business here without becoming a platform.
When you actually need platform thinking
If your customers are asking for custom scoring, their own indicator ingestion, workflow automation, multi-tenant administration, or role-based access — you're being pulled toward platform territory. The mistake teams make here is building platform features reactively, one customer request at a time, without a coherent data model underneath.
Platform architecture requires thinking about tenant isolation, configuration inheritance, API rate limits and quotas, and audit logging from early on. Bolting these on after the fact is expensive and destabilizing. If more than two enterprise prospects are asking for the same capability that doesn't exist, that's a signal to commit to the architectural decision, not defer it.
| Dimension | Pipeline Product | Platform Product |
|---|---|---|
| Primary moat | Data quality, freshness | Workflow extensibility, integrations |
| Sales motion | Bottom-up, API-first | Top-down, enterprise |
| Support burden | Low and predictable | High and bespoke |
| Time to first value | Hours | Days to weeks |
| Pricing model | Usage/feed subscription | Seat or platform fee |
| Scaling bottleneck | Data sourcing | Engineering and onboarding |
Reducing noise before it reaches customers
Alert fatigue is the product killer most threat intelligence startups underestimate. It doesn't show up in your metrics as churn — it shows up as silence. Customers stop acting on alerts. Integrations go dark. Renewal conversations become awkward because nobody remembers what your product actually does for them.
Signal scoring and filtering at ingestion
The practical question is: where do you apply intelligence? Scoring at ingestion — before data reaches customer environments — means lower volume, higher fidelity, and less compute cost on the customer side. Scoring at query time gives customers more control but pushes complexity downstream.
For most startups at early scale, scoring at ingestion with configurable override parameters is the right default. Build a confidence score into every indicator, surface it in the API response and the feed format, and let customers set minimum thresholds. This single design decision reduces support tickets by removing the "why am I seeing this alert" conversation.
Practical rule: Never ship an indicator to a customer environment without a confidence score and a source attribution. Unexplained alerts are the fastest path to distrust.
Tenant-level tuning without engineering involvement
As you add customers, tuning requests will scale faster than your engineering team. The product needs a configuration layer that lets customers — or your customer success team — adjust scoring parameters, suppress specific indicator types, or customize feed delivery cadence without code changes.
This isn't a premium feature. It's table stakes for retention. Teams that route every tuning request through engineering create a support ceiling that hard-stops growth around twenty to thirty customers.
Onboarding as a systems problem
Onboarding is where the conversion from "signed contract" to "retained customer" actually happens. Most threat intelligence startups treat it as a documentation problem or a customer success problem. It's a systems problem.
The integration gap that kills activation
The most common place threat intelligence onboarding breaks is the integration step. The customer has their SIEM. You have your feed. Getting data flowing reliably between them involves API keys, format negotiation, network allowlisting, and often internal change management on the customer side.
If your product doesn't make this integration step nearly self-service, activation rates will be low and time-to-value will be long. Both of those metrics predict churn before churn happens.
What a scalable onboarding flow actually looks like
A scalable onboarding sequence for a threat intelligence product looks like this:
- Pre-configured integration templates — publish validated connector configs for the five SIEM/SOAR platforms your customers actually use. Don't make them derive this themselves.
- Sample feed with real data — let customers validate format compatibility before they've committed engineering time. Surprises at go-live are expensive.
- Automated health check — once the integration is live, surface a status indicator that shows feed delivery, last-updated timestamp, and indicator volume. If this is broken, the customer should know before you do.
- Guided first detection — walk the customer through identifying one real alert that your feed contributed to, in their environment, within the first two weeks. This is the activation milestone that correlates most strongly with retention.
- Baseline configuration review — a short structured review at day thirty to catch tuning issues before they compound. This can be async and templated.
Data freshness and feed reliability
For threat intelligence products, reliability is the product. Not uptime — reliability of the intelligence itself. A feed that's technically available but running four hours late during an active campaign is worse than useless; it creates false confidence.
Designing for upstream failures
Your intelligence depends on upstream sources — open-source threat feeds, commercial data providers, community sharing platforms, your own collection infrastructure. Each of those can degrade or fail silently. The mistake teams make is building the happy path robustly and leaving failure handling as an afterthought.
Design your pipeline so that upstream degradation is detectable, logged, and surfaced. If a source goes stale, the customer-facing feed should reflect that — either through explicit staleness indicators or through reduced confidence scores on affected indicators. Don't let upstream failures become your product's reliability failures silently.
SLAs customers actually care about
Security teams don't care about the SLA metrics that startups like to publish. They care about: how old is this indicator when it reaches my SIEM, what happens when a source goes down, and how quickly will I know if something is wrong.
A useful way to think about it is: define your reliability commitments in terms your customers will actually act on. "99.9% API uptime" means nothing to a SOC analyst. "Indicators updated within 60 minutes of source ingestion, with explicit staleness flags when any source lags by more than 2 hours" means something concrete.
Practical rule: Publish your feed health as a customer-visible status page, not just an internal monitoring dashboard. If customers have to ask whether your data is fresh, you've already lost trust.
Go-to-market architecture for security products
Security product go-to-market is different enough from standard SaaS that generic playbooks cause real damage. The buying cycle is longer, the evaluation is more technical, and the trust bar is higher. But the principles of good GTM architecture still apply — you need repeatable motion, clear ICP, and channels that compound.
The ICP trap in threat intelligence
Many threat intelligence startups define their ICP too broadly early on. "Enterprise security teams" isn't an ICP — it's a market. The mistake teams make is pursuing any buyer who will take a call, which leads to heterogeneous customer bases with wildly different requirements that can't be served by a single product configuration.
Narrow the ICP to a specific role (SOC analyst vs. threat intelligence analyst vs. CISO), a specific use case (phishing detection vs. third-party risk vs. vulnerability prioritization), and a specific environment (cloud-native vs. hybrid vs. air-gapped). Early customers outside this ICP are often more costly than they're worth in learning value.
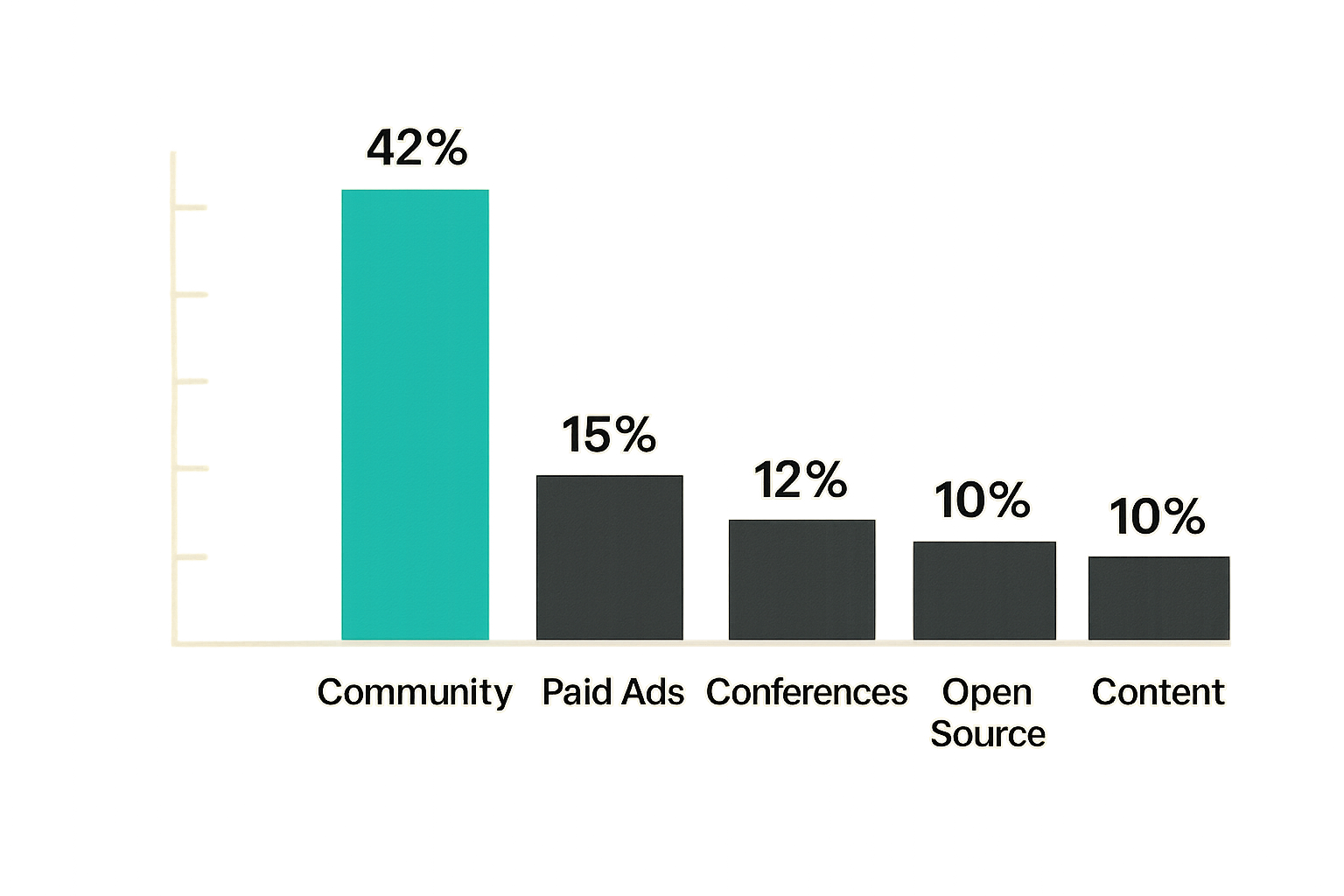
Community-led growth for security founders
Security practitioners are highly networked and skeptical of vendor marketing. The channel that consistently outperforms paid acquisition for early-stage security products is community: contributing to open-source threat intelligence projects, publishing actual research (not thought leadership), presenting at practitioner-focused conferences, and building tools that analysts use even before they need your product.
The team at threatcrush.com has observed that the security startups with the strongest early retention are almost always the ones where the founder is a credible practitioner first — someone the community already knows before the product launches. That reputation is a distribution asset that compounds in ways that ad spend doesn't.
That changes the conversation from "how do we generate leads" to "how do we build credibility at the technical level that makes practitioners want to trial the product." The answer is publishing real work: indicators, research, open tooling, analysis.
Pricing as a workflow signal
Pricing for threat intelligence products is more operationally consequential than most founders realize. The pricing model shapes how customers think about usage, which shapes the workflows they build around your product, which shapes retention.
Why seat-based pricing fights your usage patterns
Threat intelligence is not a per-user product in any meaningful operational sense. The intelligence flows into automated systems — SIEMs, SOAR playbooks, firewall blocklists — that don't have human users. Seat-based pricing creates awkward conversations about what a "seat" is and incentivizes customers to minimize the number of people touching your product, which is the opposite of the adoption behavior you want.
Consumption models and their operational overhead
Usage-based pricing (per indicator, per API call, per enrichment) aligns value delivery with cost, but it introduces budget unpredictability that makes enterprise procurement difficult and adds operational overhead to both sides. A tiered subscription model with defined volume bands is often the right middle ground — predictable for customers, aligned to actual usage patterns, and administratively simple enough that it doesn't require a dedicated billing ops function before you have one.
What breaks in production: common failure modes
A useful exercise before you add the next hundred customers: walk through the failure modes that production deployments expose.
The enrichment loop that consumes itself
This is a common failure mode in threat intelligence pipelines: an enrichment step queries an external source, which triggers a rate limit, which causes the step to retry, which amplifies the rate limit breach, which backs up the queue, which delays all downstream indicators. The entire pipeline slows to a crawl and nobody knows why until an engineer digs into logs at 2am.
Design enrichment steps with explicit circuit breakers, exponential backoff with jitter, dead-letter queues for failed enrichments, and observability on queue depth. None of this is exotic — it's standard queue hygiene — but it's frequently skipped in the early-stage rush to ship.
Alert fatigue as a churn driver
Alert volume is the most consistent leading indicator of churn in threat intelligence products, and it's almost never tracked correctly. Teams measure alert counts but not alert action rates. An analyst team that acts on 40% of your alerts is healthy. An analyst team that has stopped opening your alerts entirely is a churn risk that won't show up in your dashboard until the renewal conversation.
Instrument action rates, not just alert delivery rates. If a customer's action rate drops below a threshold, that's a support trigger — not a billing trigger.
Building feedback loops into the product
The difference between a threat intelligence product that improves and one that stagnates is usually the quality of the feedback loop between customer behavior and product development. This is a systems design question, not a product management attitude question.
Analyst feedback as a first-class data type
When an analyst marks an alert as a false positive, closes an investigation as benign, or suppresses a specific indicator — that's signal. If your product treats that as a UI action that updates a customer-specific setting and nothing else, you're discarding valuable training data.
Design the feedback capture explicitly: what signals are you collecting, how are they aggregated across tenants (while respecting data isolation boundaries), and how do they feed back into scoring logic? This doesn't require machine learning. A simple weighted decay model that lowers confidence scores for indicators with high false positive rates across multiple customers is more valuable and more operationally defensible than a complex model with opaque behavior.
Using churn signals to improve detection
Churn is data. When a customer leaves, the departure reason is almost always an intelligence quality signal: the feed had too many false positives for their environment, coverage was weak for a specific threat category they care about, or the product didn't integrate cleanly with a tool in their stack.
Build a structured offboarding process that captures this specifically — not just a generic NPS question, but a structured conversation about what the intelligence missed or got wrong. Feed those findings directly into the product roadmap.
Scaling the team without scaling chaos
Growth in a threat intelligence startup requires balancing two very different competencies: threat research (domain knowledge about adversaries, TTPs, and indicators) and software engineering (data pipelines, APIs, integrations, reliability). These teams have different instincts and different definitions of "done."
When to hire threat researchers vs. engineers
The right sequencing depends on where your competitive moat sits. If your differentiation is data quality — novel sources, better context, faster attribution — you need threat researchers early. If your differentiation is delivery, integration, and UX — getting existing intelligence to analysts faster and more clearly — you need engineers first.
The mistake teams make is hiring whatever they can get, then discovering that the new hire's skills don't match the actual bottleneck. Be explicit about where the constraint is before opening a requisition.
Knowledge transfer before it becomes a crisis
In early-stage security companies, critical knowledge lives in people's heads: how a specific data source is parsed, why a particular scoring heuristic was chosen, what a specific indicator attribute means. This is fine until the person leaves or goes on holiday during an incident.
Document the non-obvious decisions in the pipeline as you make them — not in a wiki nobody reads, but in the code itself as comments, in runbooks attached to alerts, and in onboarding documents for new analysts. The goal is that any reasonably experienced engineer or analyst can understand why the system behaves the way it does without paging the original author.
Product-market fit for threat intelligence platforms
Product-market fit in threat intelligence looks different from standard SaaS PMF signals. NPS scores are lower because security teams are professionally skeptical. Referrals are slower because procurement processes are long. The signals that actually matter are behavioral.
Retention signals that actually mean something
The metrics that correlate with genuine PMF in threat intelligence products, based on patterns across teams operating in this space: integration depth (is the customer's SIEM actually ingesting the feed, or did they just connect it once to evaluate?), analyst action rate on alerts (are analysts acting on intelligence or ignoring it?), and integration expansion (did the customer add a second integration point — say, adding firewall blocking on top of SIEM alerting — without being prompted?).
Each of those is a signal that the product has become load-bearing in the customer's security workflow. That's the retention foundation you're trying to build.
The expandable use case problem
One of the structural challenges in threat intelligence startup growth is that the core use case — feed delivery — is often commoditizable, while the differentiated value is in the surrounding workflow. Teams that recognize this early start building for use case expansion: the same customer who started with IP reputation feeds is eventually a candidate for domain monitoring, threat actor attribution, vulnerability intelligence, and supply chain risk.
Designing the data model and the pricing structure to accommodate this expansion is a growth architecture decision. If your data model makes adding a new intelligence category a major engineering project, you've constrained your expansion revenue before you even know what customers will pay for.
Where sh1pt.com fits into the growth story
Shipping velocity and the security product paradox
Threat intelligence startup growth is ultimately a shipping problem. The feedback loops in security products are long — sales cycles are measured in months, deployment timelines are slow, and customer feedback is often indirect. The teams that grow fastest are the ones that maintain high shipping velocity despite this, because they've built the product and team infrastructure to iterate without waiting for perfect information.
This is exactly the kind of problem that platforms built for indie hackers, startup founders, and product teams are designed to help with — helping you move from architecture decision to shipped feature to real customer feedback faster than your slower-moving competitors. The practical guidance on shipping cadence, product prioritization, and launch sequencing that lives on sh1pt.com applies directly to security product teams who are used to thinking about architecture but less practiced at maintaining the operational discipline of continuous delivery.
The security product paradox is that the buyers are slow but the threat landscape is fast. The only way to win that tension is to ship faster than the problem space evolves.
Try sh1pt.com
sh1pt.com is the practical resource for founders and product teams who need to move from idea to shipped product without the fluff. If you're building a threat intelligence product and trying to figure out how to translate architecture decisions into shipped features and retained customers, start here.