
A product development workflow usually breaks long before the product does.
The team is busy. Tickets are moving. Calls are happening. Someone is redesigning onboarding, someone else is fixing billing edge cases, and the founder is still collecting ideas from users, investors, competitors, and their own anxiety at 11 p.m.
Teams think the problem is speed. The real problem is decision flow.
If you cannot tell how a signal becomes a scoped bet, how that bet becomes a release, how the release is measured, and who decides what happens next, you do not have a product development workflow. You have activity. That changes the conversation. The practical question is not how to add more process. It is how to build a lightweight operating system that lets a small team ship without losing context, quality, or momentum.
Table of contents
- Product development workflow is an operating system, not a checklist
- Map the workflow from signal to shipped change
- The product development workflow stages that matter in 2026
- Scope is the control surface
- Build the release lane before you need it
- Feedback loops need ownership
- Tooling: what works and what fails
- Metrics for a healthy product development workflow
- Common failure modes in product development workflows
- A practical implementation sequence
- Where sh1pt.com fits in the product development workflow
Product development workflow is an operating system, not a checklist
The work is not linear
Most diagrams lie. They show idea, research, design, build, launch, learn. In production, the path looks messier. A customer support ticket changes the scope. A competitor launch changes positioning. A payment bug blocks onboarding work. A founder hears the same complaint three times and wants to change the roadmap by Friday.
The mistake teams make is treating the product development workflow as a phase chart. That makes the workflow look clean and the team look disorganized. A useful way to think about it is as an operating system for decisions, not a checklist for tasks.
Good workflows accept that product work loops. Signals arrive while you are building. Learning happens before launch and after launch. Support is not separate from product. Growth experiments are not separate from roadmap choices. The workflow has to preserve context across all of it.
The workflow owns decisions
A workflow should answer boring but expensive questions:
- Where do new inputs go?
- Who decides whether an input is noise, evidence, or a bet?
- What is the smallest useful version of the change?
- What must be true before it ships?
- Who watches the outcome?
- What happens if it fails?
If those questions live only in people’s heads, every project depends on memory and urgency. That works for a weekend prototype. It breaks when customers arrive, support volume increases, or more than one person can change the product.
Practical rule: if a decision changes the product, it needs a visible owner, a visible reason, and a visible next step.
The goal is controlled shipping
The goal is not process purity. Small teams do not need enterprise ceremonies. They need controlled shipping: enough structure to reduce rework, enough speed to keep learning, and enough documentation that the product does not become a private language only the original builder understands.
This matters more in 2026 because software teams can generate more code, screens, copy, and experiments than they can responsibly absorb. AI assistance makes output cheaper. It does not automatically improve judgment. If anything, it increases the need for a workflow that decides what should not be built.
Map the workflow from signal to shipped change
Start with inputs, not ideas
Most founders start with an idea backlog. That is backwards. Start with inputs. Inputs are the raw material of product development:
- customer interviews
- support tickets
- sales objections
- churn reasons
- product analytics
- onboarding recordings
- failed activation attempts
- competitor changes
- founder insight
- technical debt and platform risk
Ideas are interpretations of inputs. If you store only ideas, you lose the evidence. Three months later, nobody remembers whether a feature request came from one loud user, five paying customers, or a real activation bottleneck.
A simple input record can be enough:
- source
- user segment
- observed problem
- impact
- evidence link
- possible response
- owner
- decision status
This is also where community-driven products get interesting. If your product depends on participation, contribution, or network effects, the workflow has to capture trust signals, not just feature requests. The operating model in community building software development is a useful adjacent pattern because the product and the user loop are inseparable.
Related reading from our network: teams that manage content discovery face similar workflow tradeoffs around ownership and measurement, which is why this guide to AEO architecture for website owners is a useful comparison.
Define the decision point
Inputs should not sit forever. Every workflow needs a decision point where someone chooses one of four paths:
- ignore for now
- clarify with more research
- convert into a shaped bet
- handle as support, bug, or operational work
The decision point is not a meeting by default. It can be an async weekly review. The important part is that inputs stop drifting. Drifting inputs create phantom roadmap pressure. Everyone remembers the request, but nobody knows whether the team accepted it.
Keep launch and learning in the same map
A shipped change is not finished at deploy. It is finished when the team has learned enough to decide whether to keep, expand, revise, or remove it.
That means the workflow map should include launch, observation, and follow-up. If the map ends at merged pull request, you are optimizing engineering throughput while ignoring product truth.
A basic signal-to-shipping map looks like this:
- Capture input with source and context.
- Triage the input into ignore, research, support, or product bet.
- Shape the bet with outcome, constraints, appetite, and risks.
- Build the smallest version that can test the bet.
- Release behind the right operational guardrails.
- Watch the agreed signals.
- Decide whether to iterate, expand, or stop.
That sequence is not heavy. It is the minimum chain of custody for a product decision.
The product development workflow stages that matter in 2026
Discovery should kill weak work early
Discovery is not a research department. For small teams, discovery is the discipline of killing weak work before it consumes build time.
Useful discovery asks:
- Is this problem real for the segment we care about?
- Is the current workaround painful enough?
- Does solving it support the business model?
- Do we understand the trigger moment?
- Can we test it without building the full version?
The mistake teams make is using discovery to validate what they already want to build. That is not discovery. That is pre-sales for your own idea.
Practical rule: discovery is successful when it prevents work, not only when it approves work.
Shaping turns ambiguity into a bet
Shaping is where vague product desire becomes a buildable bet. It should define the outcome, the non-goals, the appetite, the constraints, and the expected learning.
A shaped bet for an onboarding improvement might say:
- Problem: new workspace owners do not invite teammates during setup.
- Segment: teams with 3 to 20 seats starting a trial.
- Outcome: increase first-week teammate invites.
- Appetite: three engineering days and one design day.
- Non-goals: no billing changes, no new role system.
- Risk: invites may be blocked by unclear team value, not UI friction.
- Learning plan: compare invite starts, invite completions, and trial-to-active conversion.
This is not bureaucracy. It is a compression tool. It lets builders move without asking the founder what they meant every six hours.
Build and release need different questions
Building asks: can we make this work? Releasing asks: can we expose this safely and learn from it?
Those are different questions. A feature can be technically complete and operationally unready. In small teams, this gap causes avoidable damage. A change ships without support notes. A pricing experiment launches without billing reconciliation. A UX change goes live without tracking. A migration runs with no rollback plan.
The workflow should separate done building from ready to release. One is about implementation. The other is about risk, communication, measurement, and reversibility.
Scope is the control surface
Write bets in one page
If a product bet cannot fit on one page, the team probably does not understand it yet. Long documents are not the enemy, but early length often hides unclear tradeoffs.
A one-page bet should include:
- problem
- target user
- business reason
- desired outcome
- appetite
- non-goals
- known risks
- release plan
- measurement plan
- owner
This format forces decisions. It also gives the team something to revisit after launch. Did we solve the problem we named? Did the appetite hold? Were the non-goals respected? Did the measurement plan survive contact with production?
Use appetite before estimates
Estimates ask how long the imagined solution will take. Appetite asks how much the outcome is worth. Start with appetite.
If the team says, this is worth two days, the solution changes. If the team says, this is worth six weeks, the solution changes again. Appetite protects small teams from accidentally turning every problem into a platform project.
Here is the comparison:
| Approach | Question it asks | What it encourages | Failure mode |
|---|---|---|---|
| Estimate-first | How long will this take? | Negotiating around a proposed solution | The solution becomes fixed too early |
| Appetite-first | How much is this worth? | Designing to a constraint | The team must make sharper tradeoffs |
| Deadline-first | When must it ship? | Coordination around an external event | Quality drops if scope is not cut |
| Capacity-first | Who is available? | Realistic planning | Important work can be delayed by staffing |
The practical version is simple: define appetite, shape to fit, then estimate the shaped work. If it does not fit, cut scope or reject the bet.
Cut by outcome, not by task
Bad scope cuts remove random tasks. Good scope cuts preserve the learning outcome.
Suppose you are testing whether users will import data during onboarding. Cutting the import success page might be fine. Cutting tracking is not fine. Cutting CSV edge cases might be fine. Cutting the ability to complete one clean import is not fine.
Scope control is not about doing less for its own sake. It is about protecting the reason the work exists.
Build the release lane before you need it

Feature flags are process, not polish
Feature flags are often treated as a mature-team luxury. They are actually a small-team safety mechanism. Even a simple admin-controlled flag can separate deploy from release.
That separation matters. It lets you merge code, test in production-like conditions, expose gradually, disable quickly, and coordinate messaging. Without it, every deploy becomes a public commitment.
What breaks in practice is not usually the code path. It is the lack of operational control. A risky change goes live for everyone because the team had no release lane.
QA means risk coverage
QA does not have to mean a dedicated department. It means risk coverage. Before release, ask what can break and how you would know.
For a small SaaS feature, risk coverage might include:
- primary happy path
- permission boundary
- billing or plan boundary
- mobile or small-screen behavior
- empty state
- error state
- analytics event
- support note
- rollback option
This is where product, engineering, and support overlap. If support cannot explain the change, the release is not ready. If analytics cannot detect adoption, the release is not ready. If engineering cannot roll it back, the release is not ready.
Launch notes are operational assets
Launch notes are not just marketing. They are operational assets.
A useful launch note explains:
- what changed
- who it affects
- why it matters
- how to use it
- known limitations
- support implications
- what the team is watching
For bigger releases, your launch workflow should connect positioning, docs, lifecycle messaging, and support. The guide on how to launch a software product goes deeper on treating launch as an operating workflow rather than a publish button.
Feedback loops need ownership
Instrument the few events that explain behavior
Analytics fail when teams track everything and understand nothing. You need the few events that explain the behavior your bet is trying to change.
For example, if the bet is about improving activation, the workflow might require:
- account created
- workspace configured
- first core action started
- first core action completed
- invite sent
- second session started
Do not wait until after release to define these. If measurement is added later, it becomes optional. When measurement is part of the shaped bet, it becomes a release requirement.
Separate user feedback from user demand
Users are usually good at describing pain and inconsistent at prescribing product strategy. That does not make feedback less valuable. It means your workflow has to separate the signal from the requested implementation.
A user saying, add Slack alerts, might mean:
- they miss important events
- email notifications are too noisy
- the product is not part of their daily workflow
- they need auditability
- they want their team to notice progress
The product decision is not Slack alerts. The product decision is which underlying problem matters most and what response fits your strategy.
Related reading from our network: independent writers deal with a similar distinction between client requests and actual delivery requirements, covered in this guide to AI-assisted freelance writing workflows.
Close the loop publicly when it helps
Closing the loop builds trust. If a user reported a problem and you shipped a fix, tell them. If multiple customers asked for a workflow improvement, show what changed. If you rejected a request, explain the constraint when appropriate.
This does not mean turning your roadmap into a public voting board. It means using communication as part of the product development workflow. Users should see that their input enters a real system, not a suggestion graveyard.
Practical rule: feedback without closure teaches users to stop giving feedback.
Tooling: what works and what fails
What works: one source of truth per decision
Tooling should reduce decision loss. It should not become a second product to maintain.
For small teams, the key is one source of truth per decision type:
- inputs live in one intake system
- shaped bets live in one planning space
- build work lives in one execution board
- release readiness lives in one checklist
- metrics live in one dashboard
- customer communication lives in one support or CRM tool
These can be lightweight. A folder, a board, and a spreadsheet can beat an expensive stack if ownership is clear.
What fails: status theater
Status theater happens when the tools look healthy but the workflow is not. Tickets move columns. Roadmaps have colors. Dashboards update. Nobody can explain why the work matters or what will happen after release.
The mistake teams make is buying product management software to avoid product management. Tools can store decisions. They cannot make them.
A practical tooling test:
- Can a new teammate understand why a project exists in under ten minutes?
- Can support see what changed before users ask?
- Can the founder see which bets are blocked by decisions, not tasks?
- Can engineering see the release risk before the merge?
- Can the team compare the original bet to the outcome?
If not, the tool is not the workflow. It is a filing cabinet.
The minimal stack for small teams
A small team can run a strong product development workflow with a minimal stack:
- Intake: form, inbox tag, or support view
- Research: notes database linked to user segments
- Shaping: one-page bet template
- Execution: issue tracker or kanban board
- Release: checklist with owner and rollback path
- Measurement: lightweight dashboard
- Communication: changelog, email, docs, or in-app messages
The stack matters less than the handoffs. Every handoff should preserve context: why this work exists, what is out of scope, what risk remains, and what decision comes next.
Metrics for a healthy product development workflow
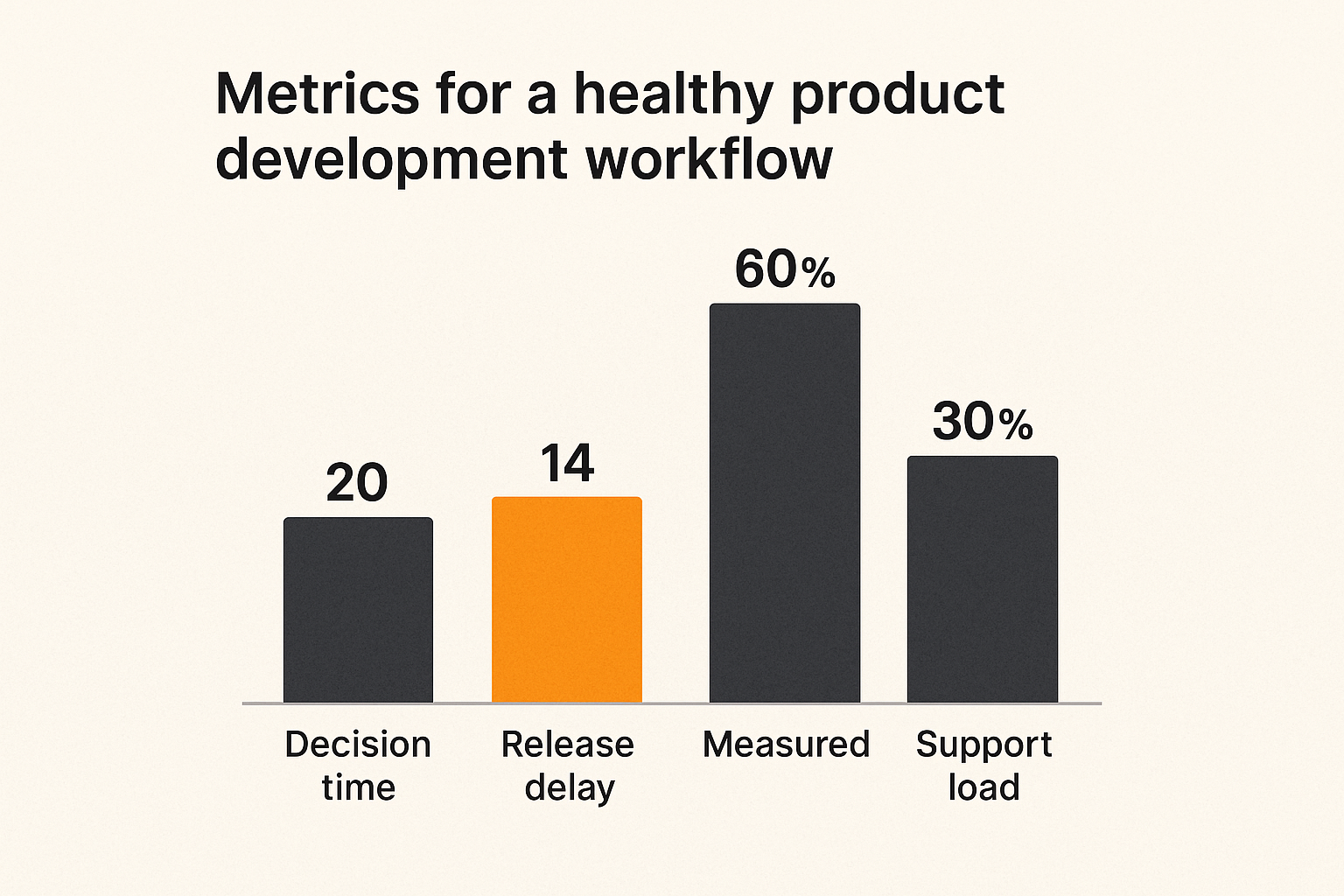
Measure flow before output
Output metrics are easy to inflate. Tickets closed, commits merged, story points completed, features launched. They can all go up while the product gets worse.
Flow metrics are harder to fake:
- time from input capture to decision
- time from shaped bet to build start
- time from build complete to release
- percentage of shipped bets with measurement defined before release
- percentage of releases with follow-up decision recorded
These metrics reveal bottlenecks. Maybe discovery is fine but shaping is slow. Maybe building is fast but releases sit unannounced. Maybe the team ships often but rarely learns.
Track decision latency
Decision latency is the time work spends waiting for a call to be made. Small teams underestimate this because waiting often looks like work. Engineers polish. Designers explore variants. PMs rewrite docs. Founders collect more opinions.
Track where decisions stall:
- problem priority
- target segment
- scope boundary
- design tradeoff
- technical approach
- launch timing
- success metric
Lower decision latency does not mean rushing. It means making uncertainty visible. A workflow that surfaces unresolved decisions early will feel less chaotic even if the team is moving fast.
For an adjacent operator view, security teams face the same ownership issue when roles blur between monitoring, investigation, and response. Related reading from our network: cybersecurity jobs as workflow ownership roles.
Watch support load after shipping
Support load is an underrated product metric. A release that increases activation but doubles confusion may still be a bad release. A feature that looks small to engineering may create operational drag if docs, permissions, billing states, or edge cases are unclear.
After shipping, watch:
- new ticket themes
- repeated user questions
- failed setup attempts
- refund or cancellation mentions
- internal escalation frequency
- time to resolution
Support is not a cleanup crew. It is part of the feedback system. If the same issue appears repeatedly, the workflow should route it back into product triage.
Common failure modes in product development workflows
The roadmap becomes a promise ledger
A roadmap should express strategic intent and sequencing. It should not become a debt ledger of everything the team once mentioned.
What breaks in practice is commitment inflation. A founder says maybe. A salesperson hears soon. A customer hears promised. The team inherits a roadmap full of emotional contracts.
Fix this by separating:
- now: committed and actively being built
- next: shaped or being shaped
- later: possible but not committed
- evidence: signals under review
- archive: rejected or obsolete
Language matters. If you do not know, say you do not know. Ambiguity is cheaper than a false promise.
Discovery and delivery split into rival teams
In larger startups, discovery and delivery often become separate camps. Product and design gather insights. Engineering receives requirements. Support hears complaints. Growth runs experiments. Everyone has partial truth.
Small teams can fall into the same trap with fewer people. The founder does discovery, the developer builds, the marketer launches, and nobody shares the same map.
The fix is not more meetings. It is shared artifacts. Inputs, shaped bets, release notes, and outcome reviews should be visible to everyone who affects the product.
Releases happen without rollback paths
A release without a rollback path is a bet with no exit. Sometimes that is unavoidable. Usually it is just neglected.
Before release, ask:
- Can we disable this feature?
- Can we revert the migration?
- Can affected users be identified?
- Can support explain the workaround?
- Can we stop rollout without another deploy?
- Can we tell whether the issue is product, data, or infrastructure?
Practical rule: the riskier the release, the more boring the rollback plan should be.
Rollback planning changes behavior. It forces the team to think about blast radius before the blast.
A practical implementation sequence
Step 1: audit the last four shipped changes
Do not redesign the whole workflow from theory. Audit recent reality.
For the last four shipped changes, write down:
- Where did the original signal come from?
- Who decided it mattered?
- Was the work shaped before building?
- What was the appetite?
- What changed during build?
- What release checklist existed?
- What was measured after launch?
- What did support hear?
- What follow-up decision was made?
- What would you do differently?
Patterns will show up quickly. Maybe your team starts too much work. Maybe you scope poorly. Maybe releases are sloppy. Maybe learning never happens. The audit gives you a workflow backlog.
Step 2: design your lane policies
Lane policies define how work moves. Keep them explicit and short.
Example lane policies:
- Input lane: every signal needs source, segment, problem, and owner.
- Triage lane: every input is reviewed weekly and assigned a path.
- Shaping lane: every bet needs outcome, appetite, non-goals, risks, and measurement.
- Build lane: every task links back to a shaped bet or operational reason.
- Release lane: every release needs risk coverage, communication, analytics, and rollback.
- Learn lane: every shipped bet gets a follow-up decision within a defined window.
This is the practical core of the product development workflow. Not a 40-page manual. Just the rules that prevent expensive ambiguity.
Step 3: run a two-week workflow pilot
Do not announce a grand process transformation. Run a pilot.
Pick one meaningful product bet. Apply the workflow from input to learning. Keep a visible log of friction:
- What felt useful?
- What felt heavy?
- Which decisions were still unclear?
- Which artifact prevented rework?
- Which checklist item caught a real issue?
- What did the team ignore?
At the end, adjust the workflow. Remove steps that did not change decisions. Strengthen steps that reduced risk. A workflow should earn its place.
If your bottleneck is speed, the operating system in shipping software faster pairs well with this approach because it treats speed as a function of scope, release ops, and ownership rather than raw coding hours.
Where sh1pt.com fits in the product development workflow
Use sh1pt.com as a shipping reference layer
sh1pt.com is for people building and launching software products who want to understand shipping strategies, product development processes, and growth tactics. That makes it most useful as a reference layer around the workflow, not as another place to collect random advice.
The product development workflow is where you decide what to build and how to ship it. A site like sh1pt.com helps with the operating patterns around that work: launch planning, shipping cadence, founder workflows, platform choices, product updates, and practical examples from teams moving from idea to market.
Use it when you are asking questions like:
- How should we structure a launch?
- What should happen before we announce?
- How do we reduce shipping drag?
- What does a good release loop look like?
- How do other builders turn messy inputs into shipped product?
When the product development workflow is ready to scale
You do not need a heavy process to scale. You need a workflow that can survive more inputs, more users, more releases, and more people touching the product.
A workflow is ready to scale when:
- inputs are captured with context
- decisions have owners
- bets are shaped before build
- scope is constrained by appetite
- release readiness is explicit
- measurement is defined before launch
- support feedback returns to product
- follow-up decisions are recorded
That is the difference between a team that ships occasionally through force of will and a team that can ship repeatedly without losing the plot.
The closing point is simple: a product development workflow is not a document you finish. It is the operating system you keep tuning as the product, team, and market change.
Try sh1pt.com
sh1pt.com is for people building and launching software products who want practical shipping strategies, product development processes, and growth tactics. Try sh1pt.com to keep improving your product development workflow.